
.png)
I came across this video of Andrej Karpathy by chance and it's a masterclass...: 3h30 of a video that really details how an AI works.
This video is not 3 hours and a half on how to use it, how to prompt, how what do I know. It's just understanding (with exceptional popularization) the main steps and key mechanisms in creating an LLM (Large Language Model).
I invite you to watch his video which is much more interesting than my summary which omits a lot of elements, as well as my level of understanding of the subject which is a millionth ofAndrej Karpathy.
For those who only have a few minutes to spare, you should understand the main mechanisms and you can easily distinguish yourself from the ambient noise about AI thanks to this summary!
PS: yes I thought about using AI to generate the article but when I saw the result, I preferred to stick to my notes ;).
1. Pre-training: when the AI reads the whole Internet
Before answering any questions, a model must... learn.
It's like for us; if we don't have knowledge, it's difficult to provide an answer (or otherwise it's called ultracrepidarianism and it's pretty fashionable). This first phase represents 90% of the cost and time allocated to the process of creating an LLM for AI companies.
There are 3 main steps:
Step 1: We download the web
The objective here is to suck up all the web, all the knowledge present, to have it ingested by the model.
So of course you have to make some adjustments so that the web is transformed into a “clean text”. For some experts, you know that there are languages used for sites and therefore tags (HTML for example). It will therefore be necessary to clean up all this in order to obtain a plain text.
Step 2: Transform text into tokens
A computer does not read text but numbers as we know.
So we will have to transform the previous text to make it intelligible. So we are going to transform words into tokens. This is the principle of tokenization.
Do you know what corresponds to?

Look carefully! It's just another compliment...in French sorry :).

And so we will convert the information from the web into a series of tokens like the extract above except that it will be... a bit longer. Yes because it will be necessary to convert the ENTIRE WEB.
Step 3: We train a neural network
We take a series of tokens (the numbers we saw earlier), we give it to the model... and the AI must guess the next token.
Oula but wait how does IT “guess” the next token (or in real life “word”)?
Well at this point, the model is just math and probability. You know when we talk about the parameters of an LLM (which has several hundreds of billions or even trillions), well at the beginning these parameters are quite random.
On the other hand, the more the model will take tokens, look for the next one, find out if it was right or not (thanks to step 1 where it sucked the web) and the more it will adjust its parameters to be more and more accurate in its predictions.
And as he's going to do it billions of times... he's going to end up being pretty good at this little game.
This step is nothing more than a gigantic “statistical autocomplete”.
At the end of this stage we are close to what we call a Base Model, or a model that:
- Recite what he saw,
- has no intention,
- Is not yet useful for conversation.
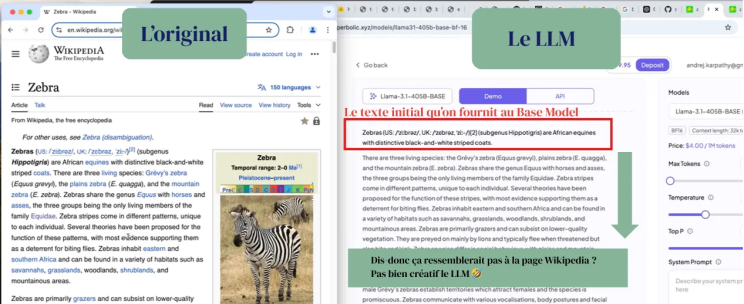
You paste a Wikipedia sentence to it, he goes on like a parrot. That is all.
Or at least like a zebra.
2. Supervised Fine-Tuning (SFT): when you teach AI to talk
This is the phase that transforms a raw model (base model) into an assistant capable of responding correctly.
Yes because let's remember, for the moment what we have is a Base Model. A model that will simply complete your sentence with elements it knows from the internet.
On this post-training phase, there is an article that seems to be the basis: “Training language models to follow instructions with human feedback” (Open AI, 2022).

So what exactly are we going to do in this stage?
We will rely on humans who will do the questions and the answers at the same time. Finally, we will show the LLM how a human asks and answers questions so that they can do the same.
Of course, before carrying out these tasks, humans have very strict instructions to follow in order to provide what we will consider to be a “good” answer. Once again, today we use LLMs (Ultrachat for example) to potentially train other LLMs in this phase since we are no longer in the infancy of LLMs.
Once we have successfully learned to make the LLM converse like a human, we will be left with a problem that is well known: hallucinations.
An LLM is still a probabilistic model : he chooses the most likely sequence, not necessarily the truest.
So we will have to teach him to know... what he does not know... Besides, it could well work for some people too.
And now we are going to have several steps to reduce this:
- Teach him to say he doesn't know.
To do this, you will choose a reliable source of information: for example the date Trump came to power during his 2nd term (yes I know there may be more pleasant information to test). You are going to ask the LLM the question and if he does not have the answer, well you will tell him: “you don't know so don't answer this question”.
- Teach him how to search on the internet.
You know sometimes when you do a search, you see that the LLM is looking on the internet. On previous versions of ChatGPT, that wasn't the case, but now it's omnipresent. Thus, research allows the LLM to limit its hallucinations.

Well from now on, it seems like we're starting to have something solid. But in reality still not, because at this stage we just have a model that has sucked the whole web and is able to speak like a human. We have just completed 2 major steps out of a total of 3.
It's an illusion but it's not enough.
Moreover, there are some who have managed to deceive for quite a long time.
3. Reinforcement: when AI learns through “trial & error”
In this final step, here is what is achieved.
We take a problem called a “problem statement” and we give it the answer. So we have the problem and the answer but not the reasoning (in blue in our diagram below):
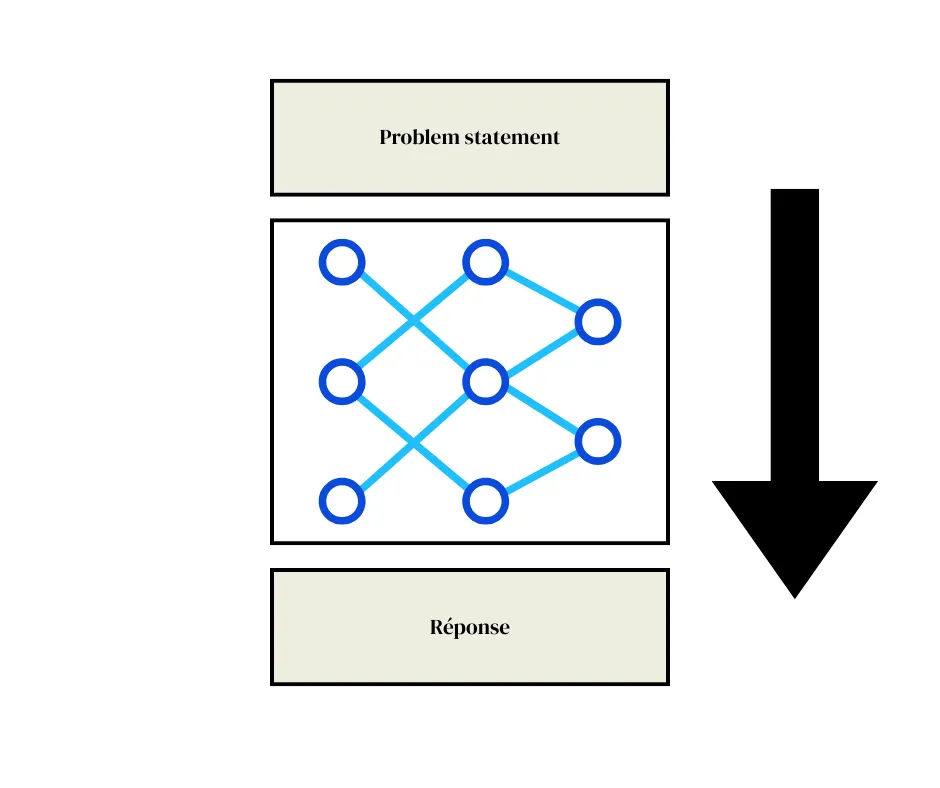
A bit like when we were in middle school and we had this rabbit by the side of the road at night. He must cross it at a particular angle. The car drives at x km/h, how fast does he have to cross in order not to end up in animal paradise? Well let's assume the answer is 21 km/h.
We will give the problem and the answer to the LLM to then select the most effective reasoning, and encourage their use in the future.
It is this “reinforcement” process that will allow the LLM to find original solutions when compared to those of humans.
For example, there is this famous ”Move 37” by AlphaGo, which is an AI playing the Chinese game of Go and which surprised everyone because although extremely effective in fine, no human would have reasonably taken the decision to play the game of Go this way.
It is at this moment that we consider AI to be "creative"...
From there, to find out if she really is... I won't allow myself to say it...
In summary
The AI we use today is based on three main building blocks, which are:
- Pre-training : the AI “sucks” the Internet, we convert sentences into tokens, and we adjust the parameters of the model by teaching it to predict the next token. We basically have a stupid model that will only complete sentences with what it knows;
- Supervised Fine Tuning (SFT) : you learn at the LLM to converse like a human... thanks to humans;
- Reinforcement : we give him a problem and a solution. He is encouraged to find the best reasoning that leads to the solution provided. Now we start to have something that can be compared to a part of creativity (intelligence?).
It's not magic, it's not conscious. But it's one of the greatest technological feats of our time.
And to understand that... is already to regain some power over these tools that are transforming our jobs.
Harold
PS: as mentioned all this information is linked to Andrej Karpathy's video “Deep Dive into LLMs like ChatGPT”: a masterclass that I barely had to transcribe 1% of in this text...