

Je suis tombé par hasard sur cette vidéo d’Andrej Karpathy et c’est une masterclass…: 3h30 d'une vidéo qui détaille réellement comment fonctionne une IA.
Cette vidéo ça n’est pas 3h30 sur comment se servir, comment prompter, comment que sais-je. C'est juste comprendre (avec une vulgarisation exceptionnelle) les grandes étapes et mécanismes clés dans la création d’un LLM (Large Language Model).
Je vous invite à regarder sa vidéo qui est largement plus intéressante que mon résumé qui omet beaucoup d’éléments, ainsi que mon niveau de compréhension du sujet qui est le millionième d'Andrej Karpathy.
Pour celles et ceux qui n'ont que quelques minutes devant eux, vous devriez comprendre les grands mécanismes et vous distinguez largement du brouhaha ambiant sur l’IA grâce à ce résumé !
PS : oui j’ai bien pensé utiliser l’IA pour générer l’article mais quand j’ai vu le résultat, j’ai préféré m’en tenir à mes notes.
1. Le pré-training : quand l’IA lit tout Internet
Avant de répondre à la moindre question, un modèle doit… apprendre.
C’est comme pour nous; si nous n’avons pas de connaissances, difficile d’apporter une réponse (où sinon ça s'appelle de l'ultracrépidarianisme et c'est plutôt à la mode). Cette première phase représente 90% du coût et du temps alloué au processus de création d'un LLM pour les entreprises de l'IA.
On note 3 grandes étapes :
Étape 1 : On télécharge le web
L’objectif ici est d’aspirer tout le web, toute la connaissance présente, pour la faire ingérer par le modèle.
Alors bien sûr il faut apporter quelques retraitements afin que le web se transforme en un “texte propre”. Pour certains connaisseurs, vous savez qu’il y a pour les sites des langages utilisés et donc des balises (HTML par exemple). Il faudra donc nettoyer tout cela afin d’obtenir un texte brut.
Étape 2 : On transforme le texte en tokens
Un ordinateur ne lit pas de texte mais des chiffres on le sait.
Alors il va falloir transformer le texte précédent pour le rendre intelligible. On va donc transformer les mots en tokens. C’est le principe de tokenisation.
Vous savez à quoi correspond ?

Cherchez bien ! C’est un compliment en plus…

Et on va donc convertir les informations du web en une suite de tokens comme l’extrait ci-dessus sauf que cela sera…un peu plus long. Oui car il faudra de quoi convertir le web dans son entièreté.
Étape 3 : On entraîne un réseau neuronal
On prend une suite de tokens (les chiffres qu'on a vus précédemment), on le donne au modèle… et l’IA doit deviner le token suivant.
Oula mais attend comment il fait pour "deviner" le token (ou dans la vie réelle “mot”) suivant ?
Et bien à ce stade, le modèle c’est juste des maths et des probabilités. Tu sais lorsqu’on parle des paramètres d’un LLM (qui en compte plusieurs centaines de milliards voire des trilliards), et bien au début ces paramètres sont tout à fait hasardeux.
En revanche plus le modèle va prendre des tokens, chercher le suivant, constater s’il a eu raison ou non (grâce à l'étape 1 où il a aspiré le web) et plus il va ajuster ses paramètres pour être de plus en plus justes dans ses prédictions.
Et comme il va le faire des milliards de milliards de fois…Il va finir par être plutôt bon à ce petit jeu.
Cette étape n’est rien d’autre qu’un gigantesque “autocomplete statistique”.
A la fin de cette étape on est proche de ce qu’on appelle un Base Model, soit un modèle qui :
- récite ce qu’il a vu,
- n’a pas d’intention,
- n'est pas encore utile pour converser.
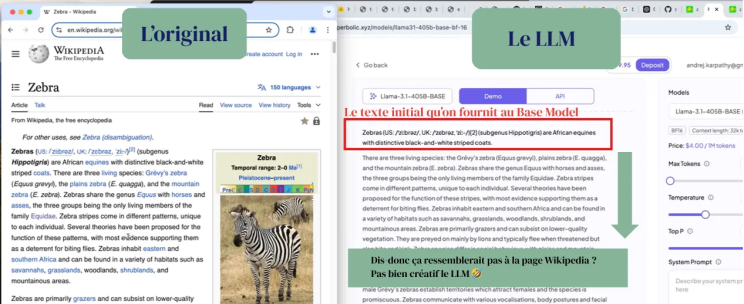
Tu lui colles une phrase Wikipedia, il continue comme un perroquet. C’est tout.
Enfin comme un zèbre plutôt.
2. Supervised Fine-Tuning (SFT) : quand on apprend à l’IA à discuter
C’est la phase qui transforme un modèle brut (base model) en assistant capable de répondre correctement.
Oui car rappelons-le, pour le moment ce qu’on a c’est un Base Model. Un modèle qui va simplement venir compléter ta phrase avec des éléments qu’il connait d’internet.
Sur cette phase de post-training, il y a un article qui semble être le socle : “Training language models to follow instructions with humain feedback” (Open AI, 2022).

Donc concrètement qu’allons-nous faire dans cette étape ?
On va s’appuyer sur des humains qui vont à la fois faire les questions et les réponses. Finalement on va montrer au LLM comment un humain pose et répond à des questions pour qu’il puisse en faire de même.
Bien sûr avant de réaliser ces tâches, les humains ont des consignes très strictes à respecter pour apporter ce qu’on va considérer comme une "bonne" réponse. Encore une fois, aujourd’hui on utilise des LLM (Ultrachat par exemple) pour entrainer potentiellement d’autres LLM à cette phase étant donné que nous ne sommes plus aux balbutiements des LLM.
Une fois qu’on a réussi à apprendre à faire converser le LLM comme un humain, il va nous rester un problème qui est bien connu : les hallucinations.
Un LLM reste un modèle probabiliste : il choisit la suite la plus probable, pas forcément la plus vraie.
Il va donc falloir qu’on lui apprenne à savoir…ce qu’il ne sait pas…D’ailleurs ça pourrait bien marcher pour certaines personnes aussi.
Et là nous allons avoir plusieurs étapes pour réduire cela :
- Lui apprendre à dire qu’il ne sait pas.
Pour cela tu vas choisir une source d’information sure : par exemple la date d’arrivée au pouvoir de Trump sur son 2ème mandat (oui je sais il peut y avoir des infos plus réjouissantes à tester). Tu vas poser la question au LLM et s’il n’a pas la réponse et bien tu vas lui dire : “tu ne sais pas donc ne réponds pas à cette question”.
- Lui apprendre à chercher sur internet.
Tu sais parfois quand tu fais une recherche, tu vois que le LLM recherche sur internet. Sur les versions précédentes de ChatGPT, ça n’était pas le cas, mais à présent c'est omniprésent. Ainsi la recherche permet au LLM de limiter ses hallucinations.

Bon à partir de maintenant, il semblerait qu’on commence à avoir quelque chose de solide. Mais en réalité toujours pas, car à ce stade on a juste un modèle qui a aspiré tout le web et qui est capable de parler comme un humain. On vient de remplir 2 grandes étapes sur un total de 3.
Ca fait illusion mais c’est pas suffisant.
D’ailleurs il y en a certains qui ont réussi à faire illusion plutôt longtemps.
3. Reinforcement : quand l’IA apprend par “trial & error”
Dans cette dernière étape, voici ce qui est réalisé.
On prend un problème qu’on appelle “problem statement” et on lui donne la réponse. On a donc le problème et la réponse mais pas le raisonnement (en bleu dans notre schéma ci-dessous) :
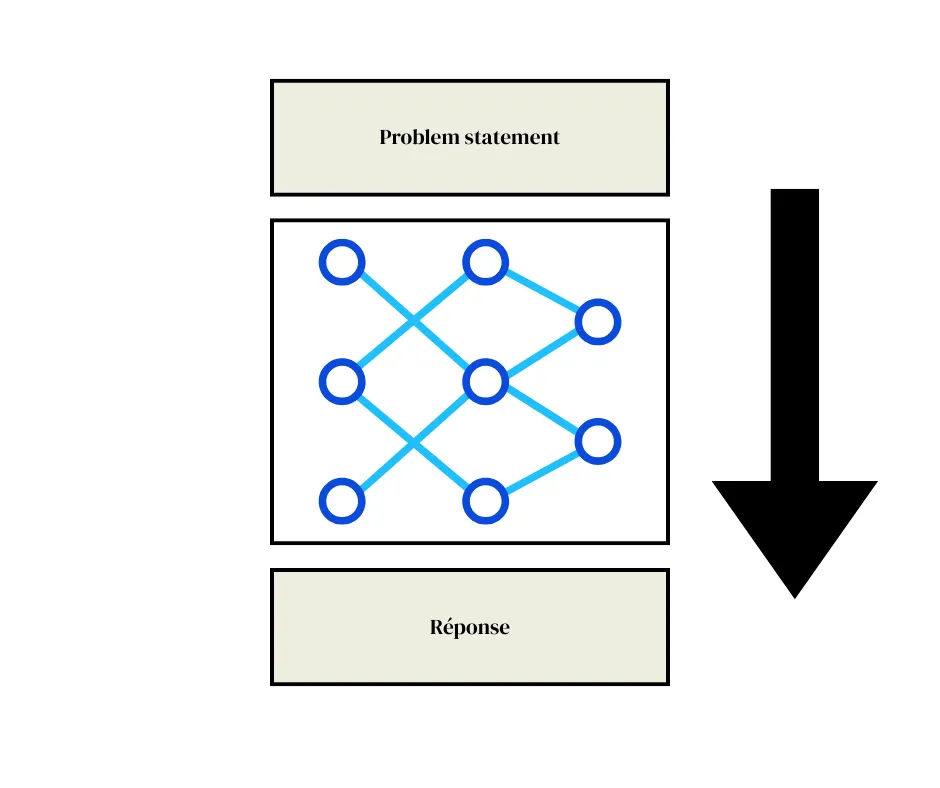
Un peu comme lorsqu’on était au collège et qu’on avait ce lapin au bord la route de nuit. Il doit la traverser avec un angle particulier. La voiture roule à x km/h, à quelle vitesse doit-il traverser pour ne pas finir au paradis des animaux ? Et bien supposons que la réponse soit 21 km/h.
Nous allons donner le problème et la réponse au LLM pour ensuite sélectionner les raisonnement les plus efficaces, et encourager leur usage à l’avenir.
C’est ce process de “reinforcement” qui permettra au LLM de trouver des solutions originales lorsqu’on les compare à celles des humains.
Il y a par exemple ce fameux “move 37” d’AlphaGo qui est une IA jouant au jeu chinois de Go et qui a surpris tout le monde car bien qu’extrêmement efficace in fine, aucun humain n’aurait raisonnablement pris le parti de jouer ce coup au jeu de Go.
C’est à cet instant qu’on considère l’IA comme créative…
De là, à savoir si elle l’est vraiment…Je ne me permettrai pas de le dire…
En résumé
L’IA que nous utilisons aujourd’hui repose sur trois grandes briques que sont :
- Pre-training : l’IA “aspire” Internet, on convertit les phrases en token, et on ajuste les paramètres du modèle en lui apprenant à prédire le prochain token. On a grossièrement un modèle bête qui ne fera que compléter des phrases avec ce qu’il sait ;
- Supervised Fine-Tuning (SFT) : on apprend au LLM à converser comme un humain…grâce à des humains
- Reinforcement : on lui donne un problème et une solution. On l’encourage à trouver le meilleur raisonnement qui permet d’aboutir à la solution fournie. Là on on commence à avoir quelque chose qui peut s’apparenter à une part de créativité (intelligence?).
C’est pas magique, c’est pas conscient. Mais c’est l’une des plus grandes prouesses technologiques de notre époque.
Et comprendre ça… c’est déjà reprendre un peu de pouvoir sur ces outils qui transforment nos métiers.
Harold
PS : comme évoqué toutes ces informations sont liées à la vidéo d’Andrej Karpathy “Deep Dive into LLMs like ChatGPT”: une masterclass dont j’ai à peine dû retranscrire 1% dans ce texte…